# **LinearRAG: Linear Graph Retrieval-Augmented Generation on Large-scale Corpora**
> A relation-free graph construction method for efficient GraphRAG. It eliminates LLM token costs during graph construction, making GraphRAG faster and more efficient than ever.
---
## 🚀 **Highlights**
- ✅ **Context-Preserving**: Relation-free graph construction, relying on lightweight entity recognition and semantic linking to achieve comprehensive contextual comprehension.
- ✅ **Complex Reasoning**: Enables deep retrieval via semantic bridging, achieving multi-hop reasoning in a single retrieval pass without requiring explicit relational graphs.
- ✅ **High Scalability**: Zero LLM token consumption, faster processing speed, and linear time/space complexity.
---
## 🎉 **News**
- **[2026-01-26]** Our **[LinearRAG](https://github.com/DEEP-PolyU/LinearRAG)** is accepted by ICLR’26.
- **[2025-10-27]** We release **[LinearRAG](https://github.com/DEEP-PolyU/LinearRAG)**, a relation-free graph construction method for efficient GraphRAG.
- **[2025-06-06]** We release **[GraphRAG-Bench](https://github.com/GraphRAG-Bench/GraphRAG-Benchmark.git)**, the benchmark for evaluating GraphRAG models.
- **[2025-01-21]** We release the **[GraphRAG survey](https://github.com/DEEP-PolyU/Awesome-GraphRAG)**.
---
## 🛠️ **Usage**
### 1️⃣ Install Dependencies
**Step 1: Install Python packages**
```bash
pip install -r requirements.txt
```
**Step 2: Download Spacy language model**
```bash
python -m spacy download en_core_web_trf
```
> **Note:** For the `medical` dataset, you need to install the scientific/biomedical Spacy model:
```bash
pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.3/en_core_sci_scibert-0.5.3.tar.gz
```
**Step 3: Set up your OpenAI API key**
```bash
export OPENAI_API_KEY="your-api-key-here"
export OPENAI_BASE_URL="your-base-url-here"
```
**Step 4: Download Datasets**
Download the datasets from HuggingFace and place them in the `dataset/` folder:
```bash
git clone https://huggingface.co/datasets/Zly0523/linear-rag
cp -r linear-rag/* dataset/
```
**Step 5: Prepare Embedding Model**
Make sure the embedding model is available at:
```
model/all-mpnet-base-v2/
```
### 2️⃣ Quick Start Example
```bash
SPACY_MODEL="en_core_web_trf"
EMBEDDING_MODEL="model/all-mpnet-base-v2"
DATASET_NAME="2wikimultihop"
LLM_MODEL="gpt-4o-mini"
MAX_WORKERS=16
python run.py \
--spacy_model ${SPACY_MODEL} \
--embedding_model ${EMBEDDING_MODEL} \
--dataset_name ${DATASET_NAME} \
--llm_model ${LLM_MODEL} \
--max_workers ${MAX_WORKERS}
# --use_vectorized_retrieval # optional, use vectorized matrix-based retrieval for GPU acceleration if Strong GPU is available, otherwise use BFS iteration.
```
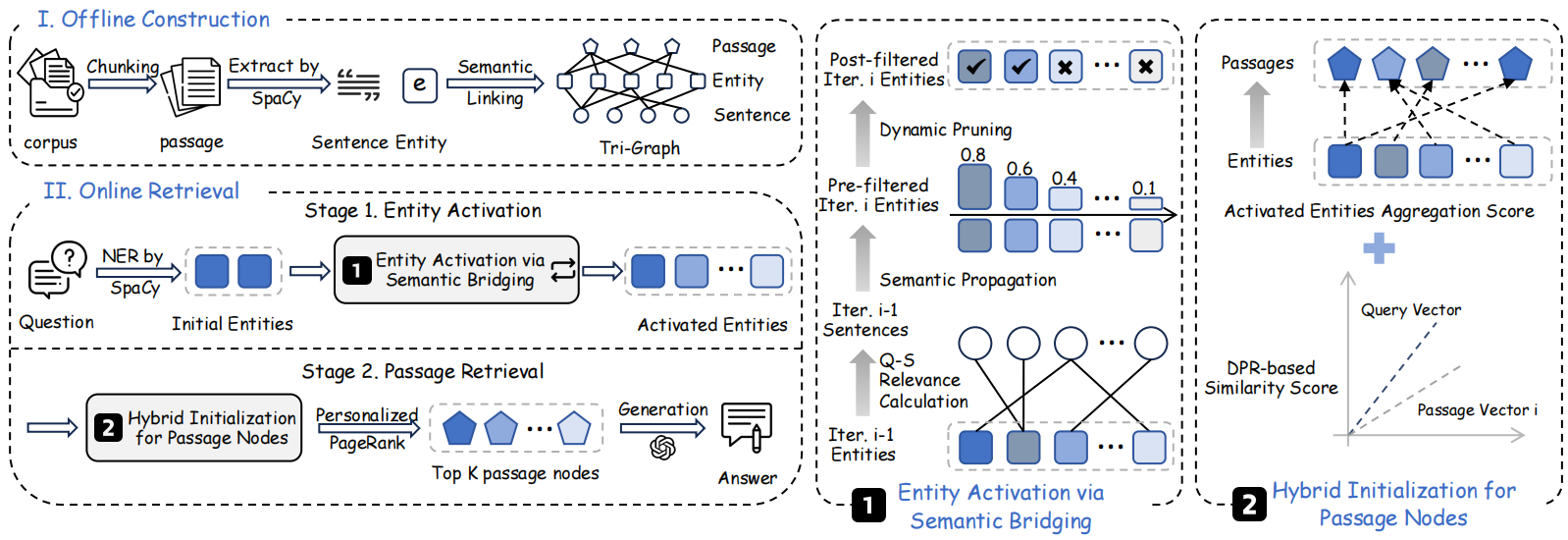
## 🎯 **Performance**
**Main results of end-to-end performance**
**Efficiency and performance comparison.**
## 📬 Citation
If you find this work helpful, please consider citing us:
```bibtex
@article{zhuang2025linearrag,
title={LinearRAG: Linear Graph Retrieval Augmented Generation on Large-scale Corpora},
author={Zhuang, Luyao and Chen, Shengyuan and Xiao, Yilin and Zhou, Huachi and Zhang, Yujing and Chen, Hao and Zhang, Qinggang and Huang, Xiao},
journal={arXiv preprint arXiv:2510.10114},
year={2025}
}
```
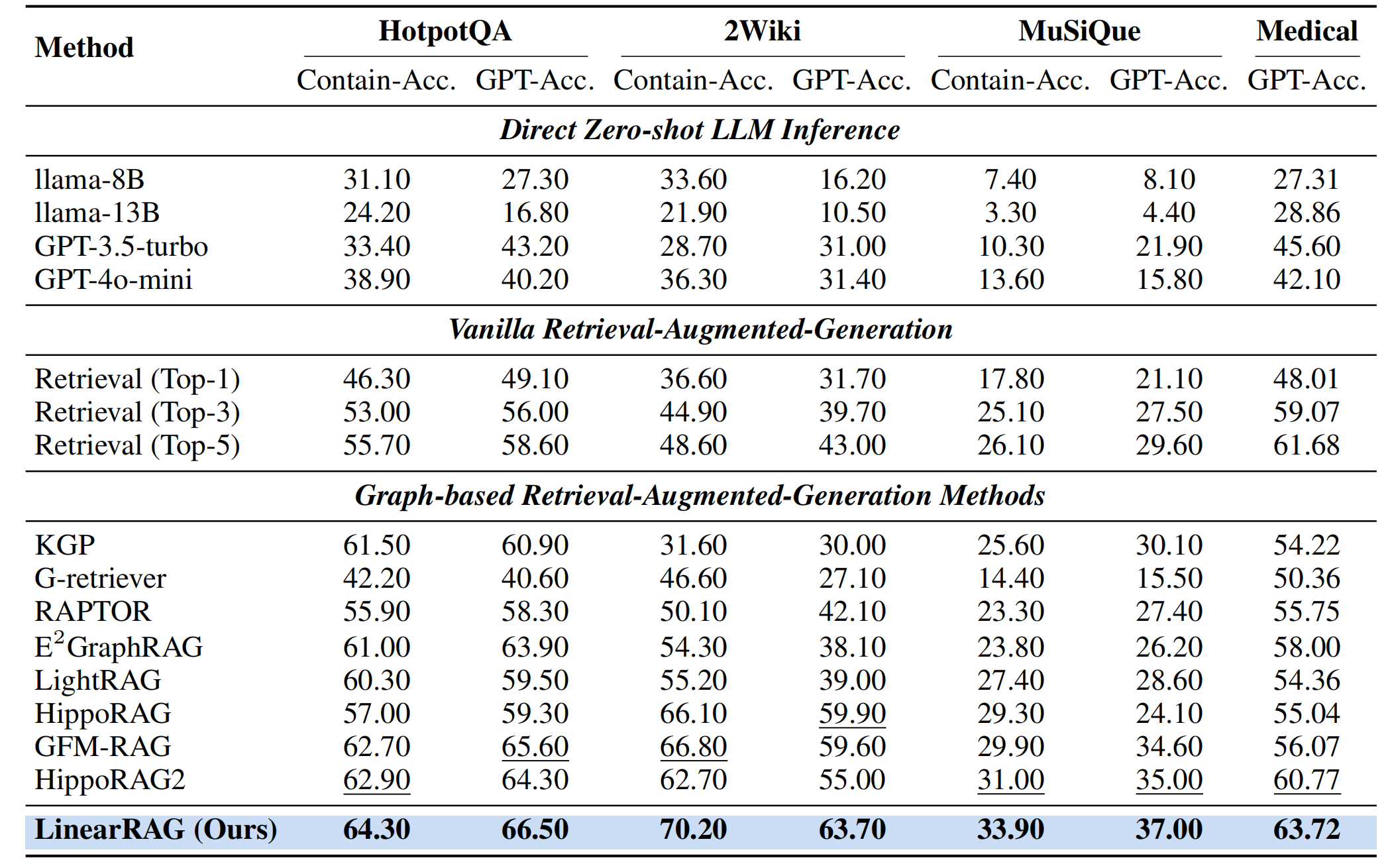 **Main results of end-to-end performance**
**Main results of end-to-end performance**
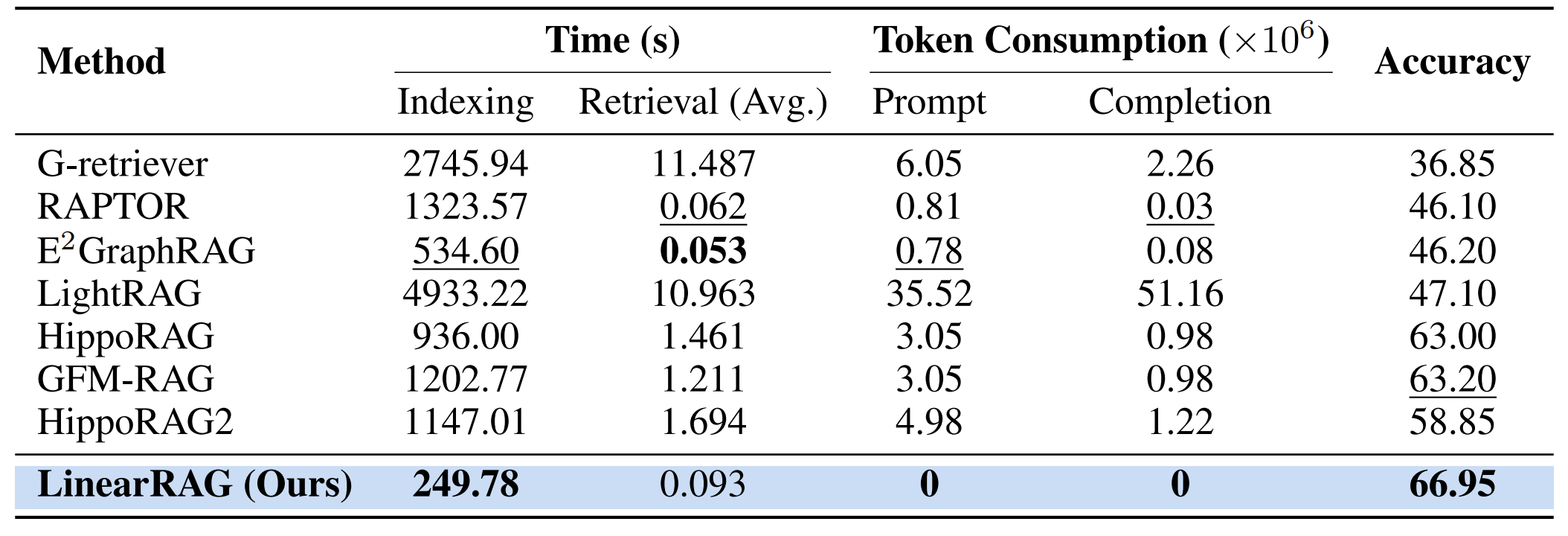 **Efficiency and performance comparison.**
**Efficiency and performance comparison.**